Tools for working with Zillow’s ZTRAX transaction and assessment data that simplify the process of importing to the data to R or loading it into SQL databases.
Installation
You can install the current version of ztraxr from GitHub with remotes:
# install.packages("remotes")
remotes::install_github("austensen/ztraxr")About ZTRAX
ZTRAX is raw public data that Zillow shares with universities and research institutions. The ZTRAX database is contains transaction and assessment data, with a total of 40 tables. The data are provided in a folder for each state with a txt file for each table. These flat files can be difficult to import into R because of their format as well as the large size of some tables.
About ztraxr
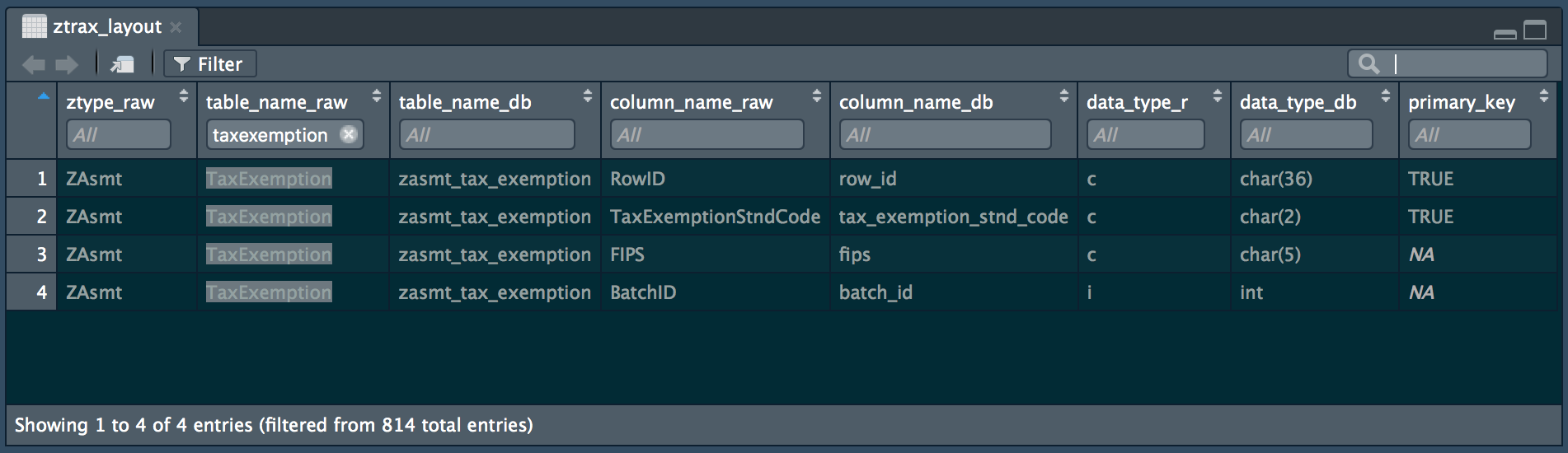
From R you can view the layouts of all tables in the ZTRAX database with the exported dataframe ztrax_layout. In addition to the original columns from ZTRAX documentation, there are also columns with the table and column names and data types as they will appear in the database. While the raw files use UpperCamelCase, they will be changed to snake_case in the database. The ztrax_lyout dataframe also contains the format in which each column will be read into R, displayed as the following standard abbreviations passed to readr::cols().
library(ztraxr)
ztrax_layout#> # A tibble: 814 x 8
#> ztype_raw table_name_raw table_name_db column_name_raw column_name_db
#> <chr> <chr> <chr> <chr> <chr>
#> 1 ZTrans ForeclosureNa… ztrans_forec… TransID trans_id
#> 2 ZTrans ForeclosureNa… ztrans_forec… FCNameAddressS… fc_name_addre…
#> 3 ZTrans ForeclosureNa… ztrans_forec… FCMailFirstMid… fc_mail_first…
#> 4 ZTrans ForeclosureNa… ztrans_forec… FCMailLastName fc_mail_last_…
#> 5 ZTrans ForeclosureNa… ztrans_forec… FCMailIndividu… fc_mail_indiv…
#> 6 ZTrans ForeclosureNa… ztrans_forec… FCMailNonIndiv… fc_mail_non_i…
#> 7 ZTrans ForeclosureNa… ztrans_forec… FCMailCareOf fc_mail_care_…
#> 8 ZTrans ForeclosureNa… ztrans_forec… FCMailFullStre… fc_mail_full_…
#> 9 ZTrans ForeclosureNa… ztrans_forec… FCMailBuilding… fc_mail_build…
#> 10 ZTrans ForeclosureNa… ztrans_forec… FCMailBuilding… fc_mail_build…
#> # ... with 804 more rows, and 3 more variables: data_type_r <chr>,
#> # data_type_db <chr>, primary_key <lgl>The ztrax_lyout dataset can be examined with View() in RStudio, where the filter options allow for quickly finding the table you are interested in or search for a particular column to see which tables in which it is included. You can also explore thi dataframe the ztraxr website.
You can import a table into R as a dataframe with read_ztrax(). In addition to dealing with the formatting issues of the flat files, this function provides a number of ways to limit the size of the final dataframe created in R to help avoid memory problems. You can reduce the dataframe’s size by specifying a subset of the table’s columns that you want to keep. If the columns are not specified they will all be included by default. The function also makes use of readr::read_delim_chunked() to import the raw data in small chunks and filter out rows you don’t need in the final dataframe. The filtering criteria can be provided as a function or formula in the style of purrr::map(), that will be passed to purrr::as_mapper() then used in the callback function used by read_delim_chunked. This filter function should take a single dataframe as the input, return the filtered dataframe, and use the raw UpperCamelCase column names. You can also specify any columns that are required for the filter function, but do not need to be included in the final dataframe.
library(dplyr)
read_ztrax(
data_dir = ztrax_example_dir(),
states = "FL",
ZType = "ZAsmt",
TableName = "TaxExemption",
KeepColumns = c("RowID", "TaxExemptionStndCode"),
FilterColumns = "FIPS",
.filter = ~ filter(., FIPS == "12086")
)#> Importing Florida
#> # A tibble: 4 x 2
#> row_id tax_exemption_stnd_code
#> <chr> <chr>
#> 1 1A284B67-3182-E711-80C2-3863BB43E814 HD
#> 2 1E284B67-3182-E711-80C2-3863BB43E814 HD
#> 3 1E284B67-3182-E711-80C2-3863BB43E814 SC
#> 4 1E284B67-3182-E711-80C2-3863BB43E814 WWWith almost the same code you can easily load the data into a table on SQL database using db_write_table_ztrax(). The function uses the metadata provided in the ZTRAX documentation (which accessible in ztrax_layout) to create the database tables using appropriate data types and also automatically designates the table’s primary keys. You can use all the same arguments as read_ztrax to select a subset of columns and/or filter the rows before loading into the table. If needed, you can recreate a table in the database with overwrite = TRUE, or simply delete a table with DBI::dbExecute(con, "DROP TABLE IF EXISTS zasmt_tax_exemption").
library(DBI)
library(purrr)
con <- dbConnect(RSQLite::SQLite(), ":memory:")
db_write_table_ztrax(
.con = con,
data_dir = ztrax_example_dir(),
states = c("FL", "NY"),
ZType = "ZAsmt",
TableName = "TaxExemption",
KeepColumns = c("RowID", "TaxExemptionStndCode", "FIPS"),
.filter = function(.data) {
.data %>%
filter(TaxExemptionStndCode == "HD")
},
overwrite = FALSE
)#> # Source: table<zasmt_tax_exemption> [?? x 3]
#> # Database: sqlite 3.22.0 [:memory:]
#> row_id tax_exemption_stnd_code fips
#> <chr> <chr> <chr>
#> 1 19884B67-3182-E711-80C2-3863BB43E814 HD 12013
#> 2 1A284B67-3182-E711-80C2-3863BB43E814 HD 12086
#> 3 1C284B67-3182-E711-80C2-3863BB43E814 HD 12013
#> 4 1D014B67-3182-E711-80C2-3863BB43E814 HD 12009
#> 5 1E284B67-3182-E711-80C2-3863BB43E814 HD 12086
#> 6 1F284B67-3182-E711-80C2-3863BB43E814 HD 12009
#> 7 1D389B67-3182-E711-80C2-3863BB43E813 HD 36005
#> 8 1A395B67-3182-E711-80C2-3863BB43E813 HD 36061
#> 9 1C435B67-3182-E711-80C2-3863BB43E813 HD 36085
#> 10 1D094B67-3182-E711-80C2-3863BB43E813 HD 36081
#> # ... with more rowsYou want to keep a record of the SQL table definitions or you want to modify them in some way before loading the data. For example, by default the RowID column is stored as char(36) for compatibility with most backends, but the column is a universally unique identifier (UUID) and you may prefer to alter the table definition to more efficiently with a data type like PostgreSQL’s uuid. Similarly, you may want to edit the table definition to specify foreign keys. To help simplify the process of writing these table definitions, you can use sql_create_table_ztrax() to generate the initial CREATE TABLE statements to edit.
When using this function all identifiers will be escaped using DBI::dbQuoteIdentifier(), conforming to the specifics of the backend of the DBIConnection object provided, otherwise DBI::ANSI() is used to generate a statement that is ANSI SQL compliant. As with the other functions, you can specify the set of columns to be included in the table, otherwise all columns are included by default. For convenience the statements are printed to the console as messages and copied to the clipboard.
sql_create_table_ztrax("ZTrans", "Main", c("TransID", "SalesPriceAmount"), con)CREATE TABLE `ztrans_main` (
`trans_id` bigint,
`sales_price_amount` decimal,
PRIMARY KEY (`trans_id`)
)sql_create_table_ztrax("ZAsmt", "TaxExemption")CREATE TABLE "zasmt_tax_exemption" (
"row_id" char(36),
"tax_exemption_stnd_code" char(2),
"fips" char(5),
"batch_id" int,
PRIMARY KEY ("row_id", "tax_exemption_stnd_code")
)